The devil is in the detail.
分布式锁的使用场景
分布式锁是为了在多进程/多机场景下避免所共享的资源被同时读写而产生以下问题:
- 同时读写,导致脏数据
- 同时读,根据读到的数据/状态做重复的操作,导致竞争、浪费资源
使用分布式锁主要是为了解决数据一致性和协调性相关的问题。
分布式锁的特性
锁的最大的特点就是互斥性,分布式锁的实现一般都是可重入的,也就是锁的拥有者在不释放锁的前提下可以进行无限次获取该锁的操作而不会死锁。这两点就和一般的锁实现一样直接利用有原子性保证的 CAS 操作就能完成。
一般的分布式锁为了避免进程/节点挂掉而导致死锁,会要求锁的持有者与分布式锁服务之间进行心跳保活,在持有者失去活性之后会在服务端隐式的释放掉相关的锁资源。
可能有个误解是如果使用 TCP 连接的话是有状态的,不需要心跳保活,实际上 TCP 连接的状态只存在于两个端点的内存里没有黑魔法:
- 在进程正常结束的情况下一般都会发送关闭信号给对端,异常结束的情况下操作系统可能帮你发 FIN 包,但这个不同的操作系统可能不一样..
- 整个操作系统挂掉、机器断电的情况下是不会发出任何数据包的,连接异常对端不可感知
- 中间数据链路比如弱网环境,路由器、网线异常就更不用说了,连接断开没有数据收发的情况下对端无法感知
其实这也是为什么 TCP 需要三次握手交换一些必要的参数,使用一个随机的 ISN,以及 TIME_WAIT 状态。TCP 默认也有 KeepAlive 不过周期一般是闲置两个小时很长。
还有一点是通过连接这一层面来做活性判断在整个网络都抖动的情况下不是很友好,如果连接断开后能马上重连就可以认为连接没有断开过,这样可以避免一次潜在的锁切换及后续状态初始化的开销,所以保活应该是更高层的抽象。
对于使用方来说,分布式锁的特点:
- 互斥性
- 可重入
- 失活(超时)被动释放
问题
可重入可能造成的问题是本地有多个线程通过同样的条件拿到锁产生竞态条件而不自知,这种程序 BUG 应该也有 :D
最大的问题是分布式锁为了避免死锁会要求锁的持有者与锁资源的提供方进行心跳保活,否则锁的提供方会主动(隐式)的释放掉这把锁:
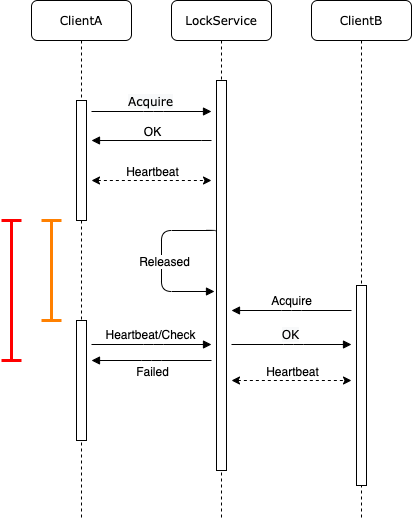
假设在黄线标示的时间范围内 ClientA 并没有主动释放锁也没有挂掉,可能由于某些奇怪的原因程序 STW/僵住,或者网络抖动丢包了,然后 LockService 释放了锁资源,这个时候 ClientB 获取到了锁资源,而对于 ClientA 而言会延时感知到锁已经易主了,即红线标示的时间范围内都认为自己还持有锁资源,默默的做一些操作,还有比较常见的是即使 ClientA 及时感知到锁已经释放了,一些正在执行的操作也无法及时终止掉。总之这个不可控的时间差在很多场景下都会造成问题。
解决方案
分布式锁能最大程度上解决一致性和协调性相关的问题,但在此之外必须根据具体的业务场景再做分析和处理。
解决方案就是保证每次操作都是 幂等 的,即同一个操作执行多次不会产生副作用。
幂等性体现在数据和状态上,落在存储里,一般从这块着手,这块主要需要搞清楚各种存储系统的并发控制和一致性语义.. 下面简要的瞎扯一下 :D
CAS
大部分数据库都提供了 CAS 这种基本的原子操作来保证数据的一致性。
假设有一个分布式的任务调度系统,通过分布式锁选举一个调度者来分配协调任务的执行,全局调度者主要是为了避免竞争并且对资源有一个全局一致的视角(一般情况下都不是瓶颈),假设有如下一个任务需要分配给某个资源充沛的节点,空代表未分配:
| name | assigned_to |
|---|---|
| task1 |
正常情况下某一时刻只有一个调度者:
| schduler | state |
|---|---|
| SchedulerA (有锁) | 本地计算中(给 task1 分配资源) |
这时发生了网络抖动或者机器负载高导致锁被隐式释放,SchedulerA 即使感知到了延时也没法立即终止本地计算的线程,此时产生了新的调度者,名义上只有一个但同时有两个进程在执行相同的资源分配逻辑:
| scheduler | state |
|---|---|
| SchedulerA (无锁) | 本地计算中(无法中断执行过程) |
| SchedulerB (有锁) | 本地计算中 |
假设 SchedulerB 先计算完成(SchedulerA 负载较高算力不行),使用 CAS 操作更改了 assigned_to:
# 注意不是客户端代码逻辑而是服务端的一个原子性操作
lock()
if assigned_to == "":
assigned_to = "node-abc"
result = success
else:
result = failed
unlock()
return result
任务的分配状态变成:
| name | assigned_to |
|---|---|
| task1 | node-abc |
SchedulerA 一段时间之后也完成了分配并使用上述 CAS 操作来更新 assigned_to 就会失败,在这种场景下这个失败是可接受的,只要保证中间计算过程没有副作用,不会影响最终结果的一致性就行。
ABA 问题
和上述场景相似但又不完全一样的是,使用 CAS 可能会出现 ABA 问题 ,某些操作被重复执行导致资源浪费、脏数据数据不一致。
延续上一个分布式任务调度系统的场景,假设 SchdulerA 还未完成计算,而 node-abc 的磁盘或者内存条损坏被回收了,管理员将下线状态告知给唯一合法的调度者 SchedulerB,SchedulerB 同时把分配状态重置为空,然后重新进行分配:
| name | assigned_to |
|---|---|
| task1 |
SchedulerA 恰好完成计算,稳定的算法,老旧的数据,选了一个坏的节点 node-abc,通过 CAS 里面的 C(比较)完成更新:
| name | assigned_to |
|---|---|
| task1 | node-abc |
SchdulerB 第二次的计算结果选择的是另一个正常的节点 node-xyz,但是使用 CAS 更新失败了,这个时候 task1 可能永远也不会被执行,或者代码还是比较完备的 SchdulerB 需要等待一定的时间才会进行重新分配 task1。
可能的解决方案比如可以设计一个粒度更细的单向的状态流转机制,或者加上版本(见下文)、时间戳(注意时间在分布式系统里面也可能会导致问题..)等等。
更复杂的场景这个例子还需要检查 assigned_to 的节点是不是活的,不是活的需要重新分配,那么在某些情况下,比如 scheduler 和被分配 的节点失活又复活的场景下,只要时间正好可能会造成其它问题,又或者任务执行状态的更新及重试等情况的引入,当然产生的影响需要视场景和需求而定。换个角度看问题或许也不一样。
多版本/并发控制
etcd/zookeeper
对于 etcd/zookeeper 这样的系统而言,支持 MVCC,每次操作服务端都会有一个版本号(全局/局部)的严格递增,类似这样:
| operation | key | value | version |
|---|---|---|---|
| PUT | foo | bar | 1 |
| PUT | foo | baz | 2 |
| DELETE | foo | 3 |
那么通过这个版本号来做 CAS 操作上述的 ABA 问题像这样解决:
# 注意不是客户端代码逻辑而是服务端的一个原子性操作
lock()
if version == vx:
value = nx
result = success
else:
result = failed
unlock()
return result
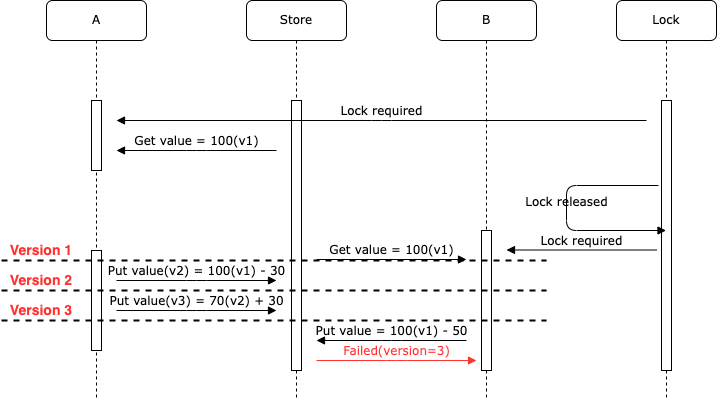 (注:此 100 非彼 100,可参考上文 ABA 问题)
(注:此 100 非彼 100,可参考上文 ABA 问题)
这里可能需要把 Lock 和 Store 合并成一个服务,但还是要看用户怎么去用 etcd/zookeeper 提供的这种语义上的分布式“锁”。
MySQL
MySQL 这块用的比较少.. MySQL InnoDB 是一个 多版本数据存储引擎,事务有 ACID 特性,其中隔离级别又分了好几种(同时影响原子性和一致性):
- READ UNCOMMITTED: 可能会出现脏读,读取到未被提交的数据
- READ COMMITTED: 可能出现幻读,同一个事务内读取同一条记录两次可能会出现不同的结果,每次读都是当前可见的最新版快照
- REPEATABLE READ: (默认),同一个事务内读取同一条记录返回的结果都一样,因为读的是第一次看到的最新版快照,这样可能会导致多个事务同时使用“老”的数据做比较判断而导致 write skew/lost update
- SERIALIZABLE: 可以认为所有并发操作都串行化了,类似加了一个全局的读写锁,所有事务都能按照执行时间排序,有严格的在前在后顺序没有同时发生的
MySQL 虽然支持 MVCC,但这个 V 是不可见的,不能像前面一样拿来做条件判断,只能使用锁和事务,那么使用 InnoDB 怎样解决脏数据的问题?
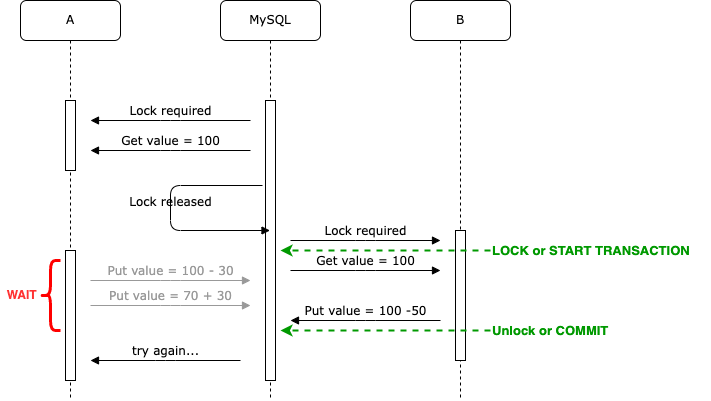 (注:此 100 非彼 100,可参考上文 ABA 问题)
(注:此 100 非彼 100,可参考上文 ABA 问题)
理论上来讲可以使用如 SELECT ... FOR UPDATE 加上一把写锁(有 NO_WAIT 之类的参数,不同隔离级别表现可能不一样?),或者使用 SERIALIZABLE 隔离级别来规避这种问题,毕竟这把锁可能会很大,复杂的场景的可能最好考虑使用额外的 Fencing(状态)机制来解决。
一致性
Designing Data-Intensive Applications 里面也提到了(非原文):数据库(这里就泛指各种存储系统了)的作用是方便存取数据,可能会提供原子性、隔离性和持久化等特性,一致性作为应用的属性由应用定义,应用层依赖数据库组件达成想要的一致性,脱离具体的需求和场景以及限制条件来谈论数据的有效性和一致性是没有意义的。
需求、场景、限制条件!!!