The devil is in the detail.
Use Cases for Distributed Locks
Distributed locks are designed to prevent shared resources from being read or written simultaneously in multi-process or multi-machine environments, which can lead to the following issues:
- Concurrent reads and writes causing dirty data
- Concurrent reads, leading to redundant operations based on the same data/state, causing contention and resource waste
The primary goal of distributed locks is to solve problems related to data consistency and coordination.
Characteristics of Distributed Locks
The key feature of a lock is mutual exclusion. Distributed locks are generally reentrant, meaning the lock holder can acquire the lock multiple times without releasing it, avoiding deadlocks. This is similar to traditional locks, which can be implemented using atomic CAS operations.
In most distributed lock implementations, to prevent deadlock caused by a process or node crash, the lock holder is required to send heartbeats to the lock service. If the lock holder becomes inactive, the lock service will implicitly release the lock.
A common misconception is that TCP connections, being stateful, do not require heartbeat mechanisms. In reality, the state of a TCP connection is only maintained in the memory of both endpoints, with no “magic”:
- When a process ends normally, it typically sends a close signal to the other side. In the event of an abnormal exit, the OS might send a FIN packet, though this behavior varies between operating systems.
- If the entire OS crashes or the machine loses power, no packets are sent, and the connection failure is undetectable by the peer.
- With weak network conditions, or issues with routers or cables, the connection can silently drop without either side being aware.
This is why TCP requires a three-way handshake to exchange necessary parameters, including random ISNs, and the TIME_WAIT state. TCP also has a KeepAlive feature, but the default idle time is usually quite long—around two hours.
Relying solely on the connection layer for liveness detection isn’t ideal in cases of network instability. If a connection drops but reconnects immediately, it’s treated as if the connection never broke, avoiding unnecessary lock switching and subsequent state initialization. Hence, liveness detection should be handled at a higher level of abstraction.
For users, the main characteristics of distributed locks are:
- Mutual exclusion
- Reentrancy
- Passive release when inactive (timeout)
Problems
A potential issue with reentrancy is that multiple local threads could acquire the lock under the same conditions, causing race conditions unknowingly — this could lead to bugs in the application :D
The biggest challenge with distributed locks is that to avoid deadlock, the lock holder must maintain a heartbeat with the lock provider. If it fails to do so, the lock provider will proactively (implicitly) release the lock:
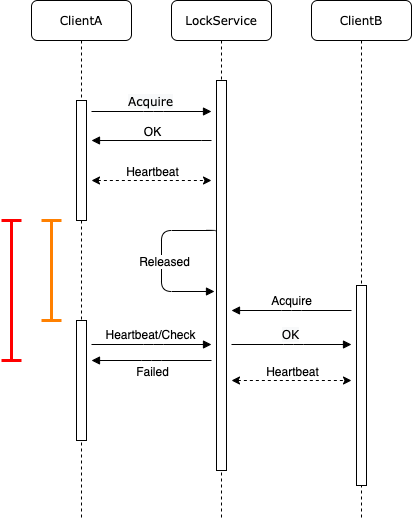
Imagine that within the timeframe marked by the yellow line, ClientA neither actively releases the lock nor crashes, but perhaps the process is stalled (due to something like a stop-the-world event or hang), or there’s network jitter and packet loss. The LockService releases the lock resource, and ClientB acquires it. Meanwhile, ClientA is delayed in realizing that the lock has been reassigned, continuing to operate under the assumption that it still holds the lock, as shown by the red line. Even if ClientA becomes aware that the lock has been released, it may not be able to immediately terminate ongoing operations. This uncontrollable delay can cause problems in many scenarios.
Solutions
While distributed locks can solve many consistency and coordination issues, you must analyze and handle specific business cases separately.
The solution is to ensure that every operation is idempotent — that is, the same operation can be performed multiple times without side effects.
Idempotency applies to data and state stored in a persistent system. This often requires an understanding of the concurrency control and consistency semantics of various storage systems. Here’s a brief (and somewhat off-the-cuff) discussion :D
CAS
Most databases provide basic atomic CAS operations to ensure data consistency.
Imagine a distributed task scheduling system that uses a distributed lock to elect a scheduler to coordinate task execution. The global scheduler is mainly to avoid competition and have a globally consistent view of resources (usually not a bottleneck). Suppose a task needs to be assigned to a resource-rich node, with an empty value indicating unassigned:
| name | assigned_to |
|---|---|
| task1 |
Normally, at any given moment, only one scheduler is active:
| scheduler | state |
|---|---|
| SchedulerA (with lock) | Processing locally (assigning task1) |
Now, imagine network jitter or heavy load causes the lock to be implicitly released. SchedulerA, even after detecting the delay, cannot immediately interrupt its local processing. Meanwhile, a new scheduler is elected, so now, although only one is active in theory, two processes are performing the same resource allocation logic simultaneously:
| scheduler | state |
|---|---|
| SchedulerA (no lock) | Processing locally (cannot interrupt) |
| SchedulerB (with lock) | Processing locally |
If SchedulerB completes first (perhaps SchedulerA is slower due to high load), it uses CAS to update the assigned_to field:
# This logic isn't client-side, but rather an atomic operation on the server
lock()
if assigned_to == "":
assigned_to = "node-abc"
result = success
else:
result = failed
unlock()
return result
The task allocation state becomes:
| name | assigned_to |
|---|---|
| task1 | node-abc |
SchedulerA finishes processing later and attempts to update assigned_to using the same CAS logic, but it fails. However, the failure is acceptable as long as the intermediate computations have no side effects, and the final result remains consistent.
ABA Problem
A similar but slightly different issue arises when using CAS — the ABA problem — where repeated operations lead to resource waste or dirty data inconsistency.
Continuing with the distributed task scheduler example, suppose SchedulerA hasn’t completed its calculation yet, but node-abc’s disk or memory fails and is reclaimed. The administrator notifies SchedulerB (the valid scheduler), and SchedulerB resets the assignment to empty and reassigns the task:
| name | assigned_to |
|---|---|
| task1 |
SchedulerA finishes its calculation, selecting the faulty node-abc (using old data) and updates the assigned_to field through CAS:
| name | assigned_to |
|---|---|
| task1 | node-abc |
SchedulerB, on its second attempt, selects a healthy node node-xyz, but its CAS operation fails. As a result, task1 may never be executed, or SchedulerB will need to wait for some time before retrying the allocation.
Potential solutions could involve designing a more granular, unidirectional state transition mechanism, adding versioning (discussed below), or using timestamps (keeping in mind that time itself can introduce issues in distributed systems).
Multi-Version/Concurrency Control
etcd/zookeeper
In systems like etcd or zookeeper, which support MVCC, each operation increments a strict version number (global or local), like so:
| operation | key | value | version |
|---|---|---|---|
| PUT | foo | bar | 1 |
| PUT | foo | baz | 2 |
| DELETE | foo | 3 |
By leveraging this version number in CAS operations, we can resolve ABA issues, like this:
# Again, this logic is server-side, not client-side
lock()
if version == vx:
value = nx
result = success
else:
result = failed
unlock()
return result
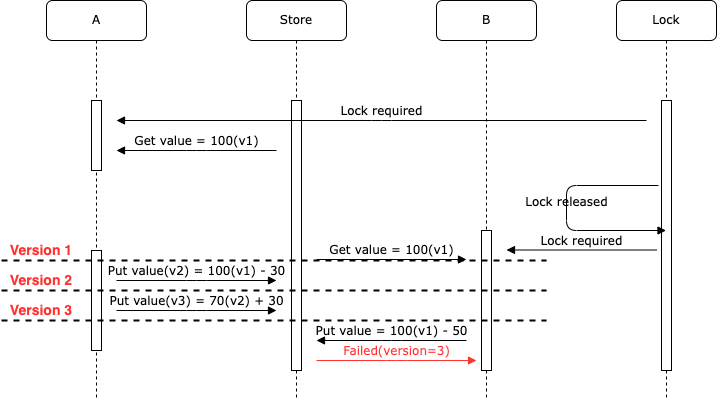 (Note: this “100” is not the same as the “100” in the previous ABA example.)
(Note: this “100” is not the same as the “100” in the previous ABA example.)
In some cases, you may need to combine Lock and Store into a single service, but that depends on how users leverage the distributed “lock” semantics provided by etcd/zookeeper.
MySQL
I don’t use MySQL much for these types of scenarios… MySQL InnoDB is a multi-version storage engine with ACID transaction guarantees. It offers several transaction isolation levels, which influence both atomicity and consistency:
- READ UNCOMMITTED: May lead to dirty reads, where uncommitted data is visible.
- READ COMMITTED: Phantom reads can occur—two reads of the same record within the same transaction may return different results.
- REPEATABLE READ: (Default) The same record always returns the same result within a transaction. However, using “stale” data can lead to write skew/lost updates.
- SERIALIZABLE: All concurrent operations are effectively serialized, behaving as if a global read-write lock is in place. Operations occur in strict order, with no concurrent transactions.
Although MySQL supports MVCC, the version number (V) is not visible for conditions like CAS. To prevent dirty data in InnoDB, you could use SELECT ... FOR UPDATE to apply a write lock (with options like NO_WAIT, depending on the isolation level), or use SERIALIZABLE isolation to mitigate such issues. However, the lock might be overly large, and for more complex scenarios, a Fencing mechanism might be needed to handle these cases.
Consistency
Designing Data-Intensive Applications also mentions (not the original text): The role of databases (here broadly referring to various storage systems) is to facilitate data storage and retrieval, and they may offer features such as atomicity, isolation, and durability. Consistency is defined as an attribute of the application and is achieved by the application layer relying on database components. Discussing the validity and consistency of data without considering specific requirements, scenarios, and constraints is meaningless.
Requirements, scenarios, constraints!!!